




In today’s AI-driven world, access to high-performance computing is critical. Researchers, developers, and startups need fast, flexible GPU resources to train machine learning models, run inference, and deploy AI solutions—but managing infrastructure can be expensive, complex, and time-consuming.
Servers fail. Setups break. Scaling becomes a headache.
That’s where Runpod changes the game.
Runpod is a cloud GPU platform designed to give teams on-demand, scalable, and cost-efficient GPU compute. By combining pay-as-you-go pods, serverless inference, and instant multi-GPU clusters, Runpod enables developers, startups, and enterprises to train, run, and deploy AI workloads without the hassle of managing infrastructure.
This article explores why GPU cloud compute is essential today, how Runpod works, and why it stands out for AI teams and growth-driven organizations.
Why Cloud GPU Compute Is Essential Today
Modern AI teams demand:
- High-performance GPUs for training and inference
- Scalable compute to handle variable workloads
- Cost-efficient pay-as-you-go infrastructure
- Easy integration with workflows, APIs, and storage
Traditional workflows often involve:
- Purchasing and maintaining expensive hardware
- Waiting for IT to provision servers
- Juggling multiple cloud platforms and contracts
- Losing time on infrastructure instead of AI development
Runpod solves these challenges by providing instant GPU access, autoscaling endpoints, and cluster orchestration—letting teams focus on building and deploying AI, not managing hardware.
A Cloud GPU Platform That Works Seamlessly

Runpod delivers a full suite of tools to accelerate AI development:
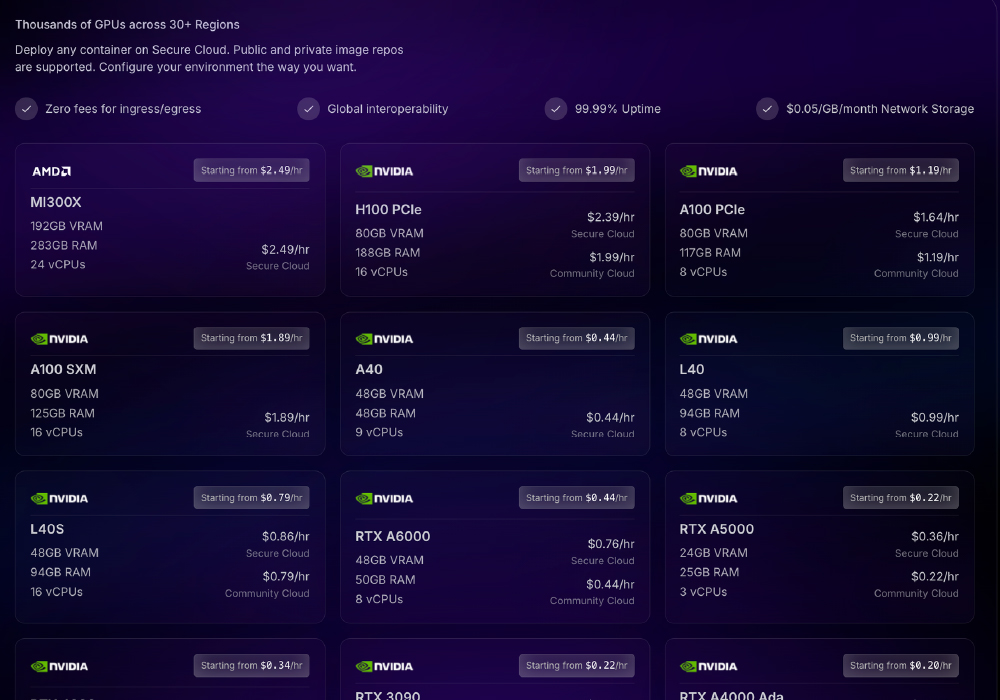
GPU Pods on Demand
- Launch high-performance GPUs instantly (H100, A100, L40S, RTX series)
- Pay per second with no long-term commitment
- Ideal for training, simulations, and experiments
Serverless Inference
- Run model inference with autoscaling workers
- Only pay for active usage
- Perfect for production APIs and real-time AI services
Instant Clusters
- Spin up multi-GPU clusters for distributed training
- Supports shared storage and high-throughput workflows
- Scale from a single GPU to hundreds in minutes
Monitoring & Reliability
- Real-time logs and metrics for debugging
- Enterprise-grade uptime and failover
- SOC 2 Type II security compliance
Global Scaling
- Deploy workloads across regions
- Optimize compute costs and reduce latency
- Autoscaling ensures compute is always available when needed
How Runpod Works: From Development to Deployment
- Spin Up GPU Pods – Choose your GPU type and launch instantly.
- Train & Test Models – Run experiments and iterate rapidly.
- Deploy & Scale – Use serverless endpoints for production workloads.
- Monitor & Optimize – Track performance, logs, and cost metrics in real time.
This workflow ensures teams spend less time on infrastructure and more time on AI development.
Built for Developers, Startups, and Enterprises
Runpod empowers:
- AI Researchers – Train models without hardware bottlenecks
- Startups – Scale GPU usage with no upfront capital expense
- Enterprises – Run large-scale distributed training and inference
- Product Teams – Deploy AI-powered applications quickly
- DevOps Teams – Automate infrastructure provisioning and scaling
By combining flexibility, performance, and automation, Runpod enables teams to focus on innovation, not hardware management.
Flexible Plans and Pricing
Runpod uses pay-as-you-go billing for maximum flexibility:
- GPU Pods: Billed by the second depending on GPU type
- Serverless Workers: Flex workers (scale to zero) or active workers (always-on)
- Instant Clusters: Hourly or enterprise custom pricing for multi-GPU setups
- Storage: Persistent storage at competitive per-GB rates
This approach lets teams optimize costs based on workload demands.
What Makes Runpod Stand Out
Unlike traditional cloud providers, Runpod combines:
- On-demand GPU access for instant compute
- Serverless endpoints that autoscale to zero
- Multi-GPU cluster deployment in minutes
- Real-time monitoring and high reliability
- Cost-efficient pay-as-you-go billing
Instead of managing infrastructure or juggling providers, Runpod lets teams train, test, and deploy AI workloads faster and smarter.
Conclusion: Where AI Ideas Become Production-Ready
Runpod represents the next generation of cloud GPU platforms. By transforming infrastructure management into instant, scalable, and cost-efficient compute, it empowers AI teams to move from experimentation to deployment quickly.
In a world where compute speed and flexibility determine success, efficiency matters.
With Runpod, every AI idea can become a production-ready solution—effortlessly.
Visit Site




